基本信息
- 标题:Rethinking Knowledge Graph Propagation for Zero-Shot Learning
- 年份:2019
- 期刊:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
- 标签:知识图谱、分类
- 数据:AwA2、ImageNet(图结构已知)
创新点
- 显式的利用知识图的层次结构通过提出的密集连通结构有效地传播知识,防止信息平滑掉。具体体现为使用层次化的父类邻接矩阵和层次化的子类邻接矩阵代替原始的邻接矩阵;并且根据父类和子类不同层次的,设置不同的权重,类似于attention机制。
- 两阶段的训练方法,第二阶段让CNN提取特征模块适配GNN学习到的分类器权重。
创新点来源
现有网络结构采用拉普拉斯算子传播节点特征信息,会导致某个节点的特征传播到远处时已经被稀释掉,从而降低网络性能。
主要内容
核心过程
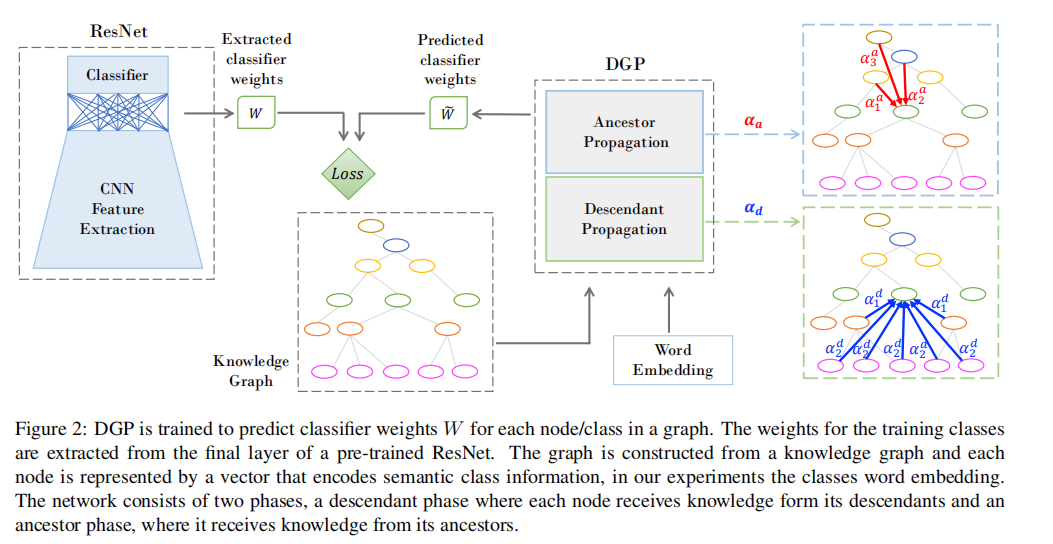
构造一个节点数等于类别数目(训练集和测试集)的拓扑图,图上的每一个节点初始值为使用Glove得到的类名的word embedding;使用wordnet得到(imagenet本身就是采用wordnet的层次结构组织的)知识图谱作为节点之间的连接;学习目标为为每一个节点上的值为是否为该类的一个分类器权重。指导信息为训练好的CNN分类模型(如resnet50)的分类器权重(只知道训练集类别的分类器权重)。其中,word embedding的作用是为每一个特定类别提供语义描述,而知识图谱可以捕捉到类别之间语义关系。
因为使用到了类名的word embedding,所以必须要知道类别的名称;同时要已知网络的拓扑结构。
问题定义
该论文主要介绍了Zero-Shot Learning,且利用了知识图谱的方法。为了描述方便,我们这里再重复介绍一个Zero-Shot Learning的定义,加深理解。
设所有的类别为$\mathcal{C}$,$\mathcal{C_{tr}}$表示训练集类别,$\mathcal{C_{te}}$表示测试集类别。Zero-Shot Learning问题中要保证$\mathcal{C}_{t e} \cap \mathcal{C}_{t r}=\emptyset$。我们给定一系列的训练样本$\mathcal{D}_{t r}=\left\{\left(\vec{X}_{i}, c_{i}\right) i=1, \ldots, N\right\}$,其中$\vec{X}_{i}$表示第$i$个训练数据,$c_{i} \in \mathcal{C}_{t r}$表示对应的类别。我们的目标为预测一系列测试数据属于哪一个$\mathcal{C_{te}}$。
GCN的定义
给定有$N$个节点,每个节点上代表一个特定的concept/class的$S$个输入特征,那么$X \in \mathbb{R}^{N \times S}$为该拓扑图的特征矩阵(在论文中,$N=32324, S=300$)。节点之间的关系采用对称矩阵$A \in \mathbb{R}^{N \times N}$表示(包含自连接),图卷积的定义式如下:
其中$H^{(l)}$表示第$l$层的输出,$\Theta \in \mathbb{R}^{S \times F}$为第$l$层的可训练权重,$\mathbb{S}$表示卷积核的数目。对于第一层,$H^{(0)}=X$,$\sigma(\cdot)$表示非线性函数。$D \in \mathbb{R}^{N \times N}$为度矩阵,$D_{i i}=\sum_{j} A_{i j}$。$D^{-1}$按行对$A$进行归一化,确保特征表达的尺度不随着$A$进行改变。
损失函数的定义
其中,$\widetilde{W} \in \mathbb{R}^{M \times P}$为GCN模型预测出的训练集类别的分类权重,$M$表示训练集的种类数,而$P$表示分类权重的维度。$W \in \mathbb{R}^{M \times P}$为真实分类权重,从预训练CNN模型中得到。论文中对这些$\widetilde{W}$和$W$均按行进行了L2正则化处理,保证它们均在一个相似的范围内。
例如在论文中,预训练CNN模型分类器权重维度为[1000, 2048];GNN模型节点数目为32324,由此可预测出32324个分类器权重,这些分类器权重总的维度为[32324, 2048],但是这32324类中只有1000类是有指导信息的,所以这里$W \in \mathbb{R}^{1000 \times 2048}$,$\widetilde{W} \in \mathbb{R}^{1000 \times 2048}$。
训练阶段:~从训练集第$i$类选取一个数据输入到GCN中,得到$\widetilde{W}_i$,将该数据输入到预训练CNN中得到${W}_i$。~训练阶段并没有用到训练集,只是用到了32324个类名的word embedding作为初始节点的特征,其中1000个类别是有监督信息的,监督信息为resnet50最后一层1000类的分类器权重。使用GNN模块使得图中每个节点的输出特征维度为2048,其中1000类的节点输出特征尽可能的接近resnet50最后一层的分类器权重。
推理阶段:~因为我们学习到的是是否属于某一类的分类器权重,所以这里的推理阶段并不像一般情况,分类出该数据属于哪一类,而是判断该数据是否属于这一类~。将CNN的分类器模块替换为GNN预测出的分类器模块,即维度由之前的[2048, 1000]替换为[2048, 32324]。取测试集的一张图片输入到改网络中,即可得到该图片属于32324类各个类别的概率,取其中最大值的下标即为预测出的类别。
这里有一个小技巧,论文中设定的为Zero-Shot Learning,也就是测试集的类别在训练集中没有出现过,因为对于一张测试集CNN输出的32324向量中,训练集的1000类可以置一个很少的数字,这样可以提高一点准确率。
改进
矩阵形式的拉普拉斯平滑算子为$\left(I-\gamma D^{-1} L\right) H$,代入拉普拉斯的算子的定义$L=D-A$,当$\gamma=1$时,可以化简为$D^{-1} A H$,正好是公式${(1)}$中的图卷积操作。因此,公式${(1)}$中的图卷积操作是一种特殊形式的拉普拉斯平滑算子,当在多层GCN结构中频繁使用该操作的话,会导致信息丢失(平滑掉了)。
DGP结构
对于该问题,论文中所提到的思路为改进公式${(1)}$中的$A$。具体做法如下:
声明邻接矩阵$A_{a} \in \mathbb{R}^{N \times N}$代表节点与其所有父节点(可能包含父节点的父节点等)的连接,$A_{d} \in \mathbb{R}^{N \times N}$代表节点与其所有子节点(可能包含子节点的子节点等)的连接,需要注意的是这两个节点均包含自连接(若不加自连接则全部信息均来自其邻接节点,抛弃了自身节点的信息,这显然不切合实际)。我们可以得到$A_{d}=A_{a}^{T}$,例如,当$A_a\{1,2\}=1$时表示节点1的祖先为节点2,那么在$A_{d}$中$A_d\{2,1\}=1$表示节点2的后代为节点1,两者含义相同。取而代之的GCN公式${(1)}$为:
采用这种方式,可以使用到知识图谱的层次结构,节点可以从其所有祖先和所有后代获得较远的信息,避免了只从邻接节点获得较远信息时的信息丢失。如下图所示:
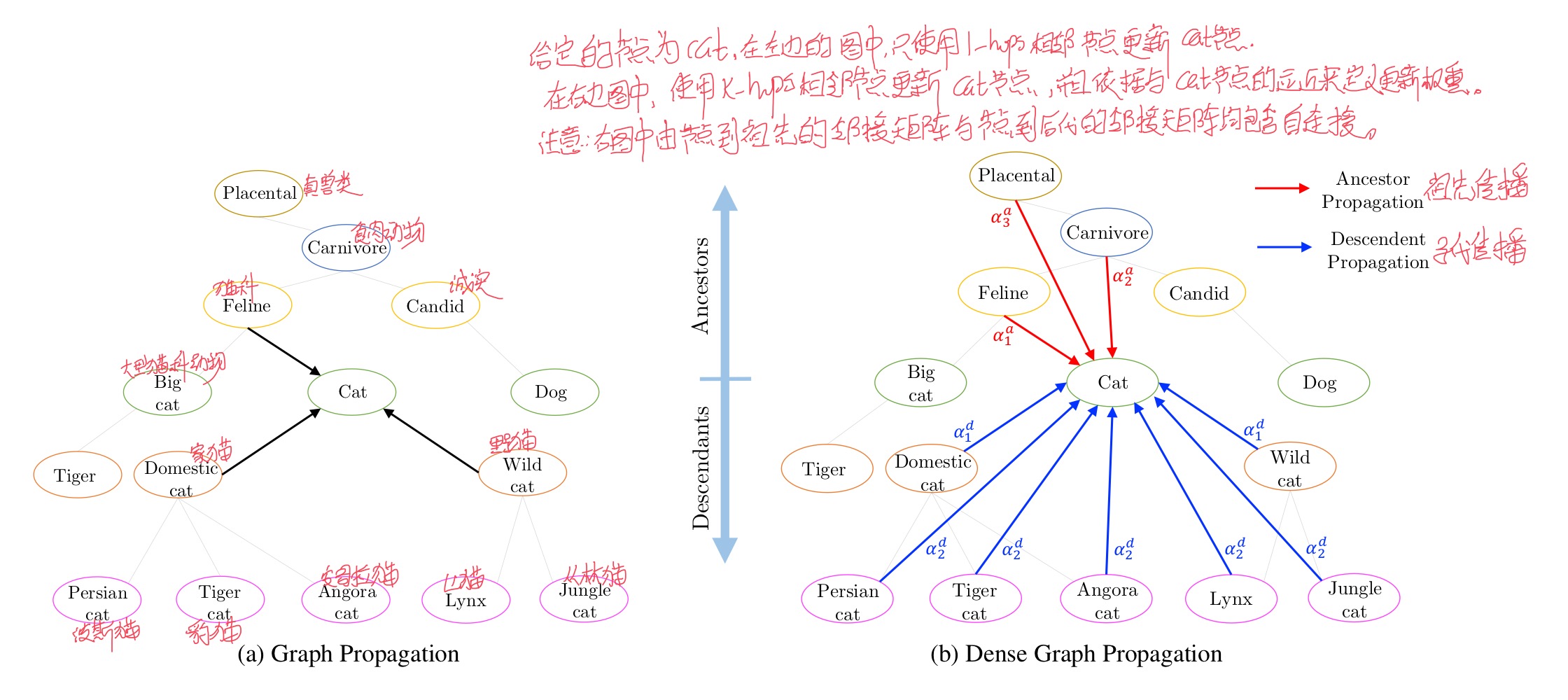
但是这样还存在一个问题,一个节点的祖先和后代可能有很多个,也分为不同的层次,不同层次的祖先和后代对节点的信息更新贡献应该是不同的。因此,论文使用$w^{a}=\left\{w_{i}^{a}\right\}_{i=0}^{K}$和$w^{d}=\left\{w_{i}^{d}\right\}_{i=0}^{K}$分别表示祖先和后代传播阶段的学习权重。$w^a$和$w^d$分别由K个值组成,$w_{i}^{a}$ 矩阵表示与节点的距离为$i$的祖先节点权重,$w_{i}^{d}$表示与节点距离为$i$的后代节点权重,这里所说的距离为节点之间在拓扑图上的距离。例如$w_{0}^{a}, w_{0}^{d}$表示自连接权重,$w_{K}^{a}, w_{K}^{d}$表示与节点距离大于$K-1$的祖先节点和后代节点权重。使用softmax函数对权重归一化,防止更新后节点特征值过大。
这样,公式${(3)}$就变成了
其中,$A_{k}^{a}$ 和 $A_{k}^{d}$表示与节点距离为$k-hop$的祖先和后代,$D_{k}^{a}$ 和 $D_{k}^{d}$为对应的度矩阵。这里增加了$2 \times(K+1)$参数量(论文中$K=4$)。这种策略很像CNN中的attention机制,但是没有增加太多参数量,所以不会导致过拟合。
注意这里的$\alpha_{k}^{a}$和$\alpha_{k}^{d}$均为标量,需要跟矩阵中所有的值相乘。
最终,DGP整体结构如下:
Finetuning
训练分为两个部分,在第一阶段训练DGP得到维度为$N \times P$的所有类别的分类器权重,其中对应于训练集类别的分类器权重子矩阵$\widetilde{W}$维度为$M\times P$。为了让预训练CNN特征提取模块适应新的分类器权重,固定预训练CNN的最后的分类层为DGP学习到的分类器权重$\widetilde{W}$,在训练集上调整预训练CNN的特征提取模块。
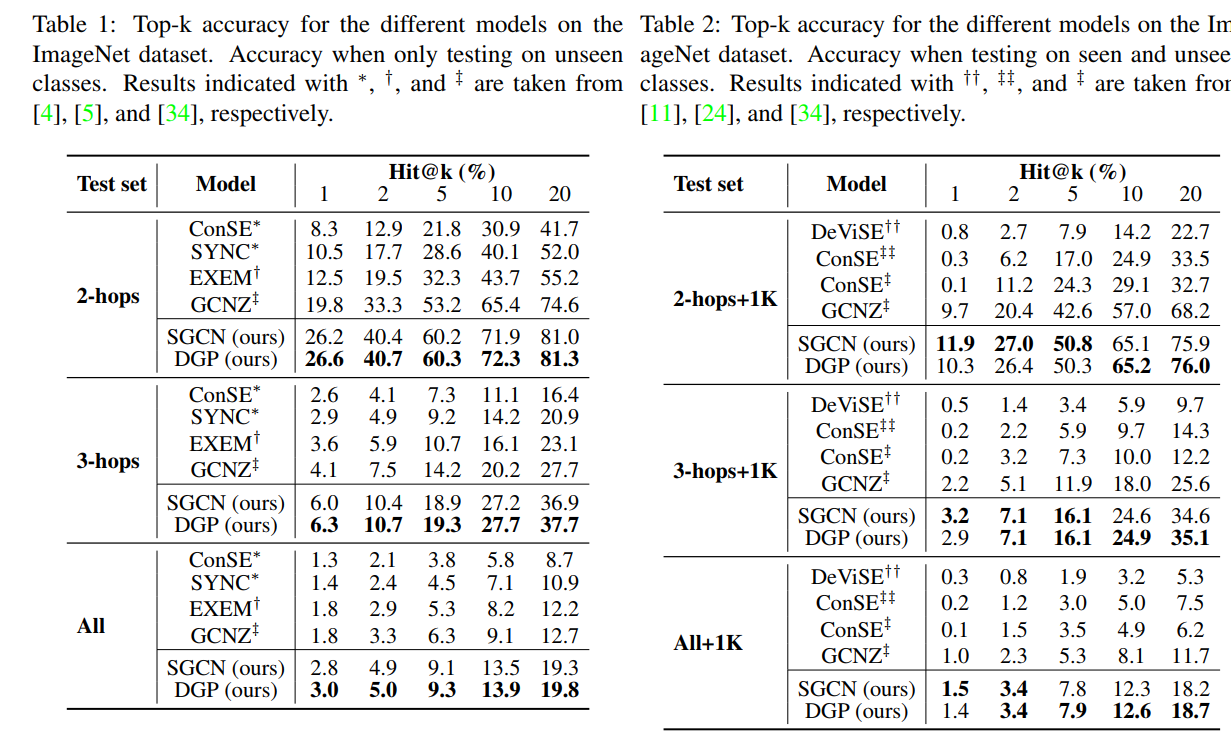
实验结果
其中,SGCN为公式${(1)}$中的单层GCN。
缺点
- 需要已知拓扑结构,需要已知所有类别的类名(包括测试集的类名)。
- 依赖于预训练CNN的性能,且理论上分类性能不会超过预训练CNN的精度。
- 训练GNN过程中,并没有利用到数据集,只是使用了类名的word embedding和预训练CNN的分类器权重。这样导致的后果可能是较高的依赖类名的word embedding性能。
- 现有的GNN模型节点数为32324类,不管是拉普拉斯矩阵的计算,还是图卷积的操作,复杂度都较高。所以GNN层为2层,相比动辄几十层的CNN,层数较少。
- 现在每一个层次的节点矩阵均对应于一个权值,可以考虑每一个层次的节点矩阵均对应于权值矩阵。因为不同节点的同一层次的父类(子类)节点对该节点的贡献应该是不同的。但是这样也增加了复杂度。
启发
是否能够更改分类器权重之间差别的衡量准则,进而改进损失函数
训练GNN的过程中,能够将数据中所包含的信息和类别名的word embedding信息结合起来
- 现在是两阶段训练的方法,能否找到一种端到端的训练方案
思考
运用知识图谱的方法训练Zero-Shot Learning,要构建节点数为总类别数的知识图谱,其拓扑结构是由wordnet提供的,初始值是每个类别名的word embedding,最终目标为使得知识图谱的每一个节点上的值代表该类的分类器权重。imagenet作为规模庞大的数据集,其类别数目高达21K,而常见的CNN模型只用到其不重合的1K种。
由此构建出规模为21K的知识图谱,将预训练CNN分类层的1K个分类器权重作为类标,使得知识图谱中对应的1K个类别的分类器权重与其差别最小。通过这个过程,可以看出除了常见的1K类之外,其余类别的分类器权重的信息均来自于这1K类的分类器权重。根据GNN和imagenet数据集的特性,可以看出两者均比较适合这种方法。

